Setup an LLM provider
‘tidyprompt’ can be used with any LLM provider capable of completing a chat.
At the moment, ‘tidyprompt’ includes pre-built functions to connect with various LLM providers, such as Ollama, OpenAI, OpenRouter, Mistral, Groq, XAI (Grok), and Google Gemini.
With the llm_provider-class, you can easily write a hook
for any other LLM provider. You could make API calls using the ‘httr2’
package or use another R package that already has a hook for the LLM
provider you want to use. If your API of choice follows the structure of
the OpenAI API, you can call llm_provider_openai() and
change the relevant parameters (like the URL and the API key).
# Ollama running on local PC
ollama <- llm_provider_ollama(
parameters = list(model = "llama3.1:8b"),
)
# OpenAI API
openai <- llm_provider_openai(
parameters = list(model = "gpt-4o-mini")
)
# Various providers via OpenRouter (e.g., Anthropic)
openrouter <- llm_provider_openrouter(
parameters = list(model = "anthropic/claude-3.5-sonnet")
)
# ... functions also included for Mistral, Groq, XAI (Grok), and Google Gemini
# ... or easily create your own hook for any other LLM provider;
# see ?`llm_provider-class` for more information; also take a look at the source code of
# `llm_provider_ollama()` and `llm_provider_openai()`. For APIs that follow the structure
# of the OpenAI API for chat completion, you can use `llm_provider_openai()`Basic prompting
A simple string serves as the base for a prompt.
By adding prompt wraps, you can influence various aspects of how the LLM handles the prompt, while verifying that the output is structured and valid (including retries with feedback to the LLM if it is not).
"Hi there!" |>
send_prompt(ollama)
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> Hi there!
#> --- Receiving response from LLM provider: ---
#> How's your day going so far? Is there something I can help you with or would you like to chat?
#> [1] "How's your day going so far? Is there something I can help you with or would you like to chat?"add_text() is a simple example of a prompt wrap. It
simply adds some text at the end of the base prompt.
"Hi there!" |>
add_text("What is a large language model? Explain in 10 words.") |>
send_prompt(ollama)
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> Hi there!
#>
#> What is a large language model? Explain in 10 words.
#> --- Receiving response from LLM provider: ---
#> Advanced computer program trained on vast amounts of written data.
#> [1] "Advanced computer program trained on vast amounts of written data."You can also construct the final prompt text, without sending it to an LLM provider.
"Hi there!" |>
add_text("What is a large language model? Explain in 10 words.")
#> <tidyprompt>
#> The base prompt is modified by a prompt wrap, resulting in:
#> > Hi there!
#> >
#> > What is a large language model? Explain in 10 words.
#> Use 'x$base_prompt' to show the base prompt text.
#> Use 'x$construct_prompt_text()' to get the full prompt text.
#> Use 'get_prompt_wraps(x)' to show the prompt wraps.Prompt wraps
This package contains three main families of pre-built prompt wraps which affect how a LLM handles a prompt:
-
answer_as: specify the format of the output (e.g., integer, list, json) -
answer_by: specify a reasoning mode to reach the answer (e.g., chain-of-thought, ReAct) -
answer_using: give the LLM tools to reach the answer (e.g., R functions, R code, SQL)
Below, we will show examples of each type of prompt wrap.
answer_as: Retrieving output in a specific format
Using prompt wraps, you can force the LLM to return the output in a specific format. You can also extract the output to turn it from a character into another data type.
For instance, answer_as_integer() adds a prompt wrap
which forces the LLM to reply with an integer.
To achieve this, the prompt wrap will add some text to the base
prompt, asking the LLM to reply with an integer. However, the prompt
wrap does more: it also will attempt to extract and validate the integer
from the LLM’s response. If extraction or validation fails, feedback is
sent back to the LLM, after which the LLM can retry answering the
prompt. Because the extraction function turns the original character
response into a numeric value, the final output from
send_prompt() will also be a numeric type.
"What is 2 + 2?" |>
answer_as_integer() |>
send_prompt(ollama)
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> What is 2 + 2?
#>
#> You must answer with only an integer (use no other characters).
#> --- Receiving response from LLM provider: ---
#> 4
#> [1] 4Below is an example of a prompt which will initially fail, but will
succeed after llm_feedback() and a retry.
"What is 2 + 2?" |>
add_text("Please write out your reply in words, use no numbers.") |>
answer_as_integer(add_instruction_to_prompt = FALSE) |>
send_prompt(ollama)
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> What is 2 + 2?
#>
#> Please write out your reply in words, use no numbers.
#> --- Receiving response from LLM provider: ---
#> Four.
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> You must answer with only an integer (use no other characters).
#> --- Receiving response from LLM provider: ---
#> 4
#> [1] 4‘tidyprompt’ offers various other ‘answer_as’ functions, such as
answer_as_boolean(), answer_as_regex_match(),
answer_as_named_list(), answer_as_text() and
answer_as_json().
JSON output
answer_as_json() may be especially powerful when your
LLM provider and model have native support for returning JSON objects
and adhering to JSON schemas (e.g., OpenAI, Ollama). Text-based handling
is however always possible, also for providers which do not natively
support such functions. This means that you can always switch between
providers while ensuring the results will be in the correct format.
It should also be noted that native JSON enforcement may also restrict the model too much, so it is always good to test and see what works best for your use case. In our experience, text-based handling is often more flexible and robust, especially when combining multiple prompt wraps. Note also that JSON schemas may not enforce all qualities you are looking for in the output, so you may still need to add additional prompt wraps to ensure the output is as desired.
answer_by: Adding a reasoning mode to the LLM
Prompt wraps may also be used to add a reasoning mode to the LLM. It is hypothesized that this could improve the LLM’s performance on more complex tasks.
For instance, answer_by_chain_of_thought() will add
chain of thought reasoning mode to the prompt evaluation by the LLM. The
function wraps the base prompt text within a request for the LLM to
reason step by step, asking it to provide the final answer within
‘FINISH[
"What is 2 + 2?" |>
answer_by_chain_of_thought() |>
answer_as_integer() |>
send_prompt(ollama)
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> You are given a user's prompt.
#> To answer the user's prompt, you need to think step by step to arrive at a final answer.
#>
#> ----- START OF USER'S PROMPT -----
#> What is 2 + 2?
#>
#> You must answer with only an integer (use no other characters).
#> ----- END OF USER'S PROMPT -----
#>
#> What are the steps you would take to answer the user's prompt?
#> Describe your thought process in the following format:
#> >> step 1: <step 1 description>
#> >> step 2: <step 2 description>
#> (etc.)
#>
#> When you are done, you must type:
#> FINISH[<put here your final answer to the user's prompt>]
#>
#> Make sure your final answer follows the logical conclusion of your thought process.
#> --- Receiving response from LLM provider: ---
#> Here are my thought steps:
#>
#> >> step 1: Understand the question - The prompt asks for the result of a simple arithmetic operation, specifically adding 2 and 2.
#>
#> >> step 2: Recall basic math facts - I recall that the sum of two identical numbers is equal to twice the value of each number. In this case, both numbers are 2.
#>
#> >> step 3: Apply the math fact - Using the knowledge from step 2, I calculate the result by multiplying 2 (the number being added) by 2 (the other number), which gives 4.
#>
#> >> step 4: Confirm the answer - Before providing a final response, I confirm that my calculation is correct. Adding 2 and 2 indeed equals 4.
#>
#> FINISH[4]
#> [1] 4answer_using: Have the LLM work with tools and code
Tools (function-calling)
With answer_using_tools(), you can enable your LLM to
call R functions. This enables the LLM to autonomously retrieve
additional information or take other actions.
answer_using_tools() automatically extracts
documentation when it is available for base R functions and functions
from packages. Types are inferred from the default arguments of the
function. If you want to define a custom function and/or override the
default documentation, you can use tools_add_docs(). See
example usage in the documentation of
answer_using_tools().
answer_using_tools() supports both text-based function
calling and native function calling (via API parameters, currently
implemented for OpenAI and Ollama API structures).
"What are the files in my current directory?" |>
answer_using_tools(list.files) |>
send_prompt(ollama)
#> ! `answer_using_tools()`, `tools_docs_to_text()`:
#> * Argument 'pattern' has an unknown type. Defaulting to 'string'
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> What are the files in my current directory?
#>
#> If you need more information, you can call functions to help you.
#>
#> To call a function, output a JSON object with the following format:
#> {
#> "function": "<function name>",
#> "arguments": {
#> "<argument_name>": <argument_value>,
#> # ...
#> }
#> }
#> (Note: you may not provide function calls as function arguments.)
#>
#> The following functions are available:
#>
#> function name: list.files
#> description: List the Files in a Directory/Folder: These functions produce a character vector of the names of files
#> or directories in the named directory.
#> arguments:
#> - path: a character vector of full path names; the default corresponds to the working directory, 'getwd()'. (...) [Type: string]
#> - pattern: an optional regular expression. Only file names which match the regular expression will be returned. [Type: unknown]
#> - all.files: a logical value. If 'FALSE', only the names of visible files are returned (following Unix-style visibility, that is files whose name does not start with a dot). If 'TRUE', all file names will be returned. [Type: logical]
#> - full.names: a logical value. If 'TRUE', the directory path is prepended to the file names to give a relative file path. If 'FALSE', the file names (rather than paths) are returned. [Type: logical]
#> - recursive: logical. Should the listing recurse into directories? [Type: logical]
#> - ignore.case: logical. Should pattern-matching be case-insensitive? [Type: logical]
#> - (...)
#>
#> After you call a function, wait until you receive more information.
#> Use the information to decide your next steps or provide a final response.
#> --- Receiving response from LLM provider: ---
#> To get the files in my current directory, I will call the `list.files` function with the necessary arguments.
#>
#> Here's the JSON object:
#>
#> ```
#> {
#> "function": "list.files",
#> "arguments": {
#> "path": "."
#> }
#> }
#> ```
#>
#> This will list the files in the current working directory. The argument `path` is set to `"."`, which corresponds to the current working directory, and I'm not providing any pattern or other arguments as they are optional.
#>
#> Let's see what happens next...
#> --- Sending request to LLM provider (llama3.1:8b): ---
#> function called: list.files
#> arguments used: path = .
#> result: getting_started.Rmd, getting_started.Rmd.orig, man, precompile vignettes.R, sentiment_analysis.Rmd, sentiment_analysis.Rmd.orig
#> --- Receiving response from LLM provider: ---
#> It looks like I have a mix of files in my current directory.
#>
#> The `list.files` function returned a list of file names, which are:
#>
#> * `getting_started.Rmd`
#> * `getting_started.Rmd.orig`
#> * `man`
#> * `precompile vignettes.R`
#> * `sentiment_analysis.Rmd`
#> * `sentiment_analysis.Rmd.orig`
#>
#> These files seem to be related to some kind of project or documentation.Code generation and evaluation
answer_using_r() provides a more advanced prompt wrap,
which has various options to enable LLM code generation. R code can be
extracted, parsed for validity, and optionally be evaluated in a
dedicated R session (using the ‘callr’ package). The prompt wrap can
also be set to ‘tool mode’ (with output_as_tool = TRUE),
where the output of R code is returned to the LLM, so that it can be
used to formulate a final answer.
# From prompt to ggplot
plot <- paste0(
"Create a scatter plot of miles per gallon (mpg) versus",
" horsepower (hp) for the cars in the mtcars dataset.",
" Use different colors to represent the number of cylinders (cyl).",
" Make the plot nice and readable,",
" but also be creative, a little crazy, and have humour!"
) |>
answer_using_r(
pkgs_to_use = c("ggplot2"),
evaluate_code = TRUE,
return_mode = "object"
) |>
send_prompt(openai)
plot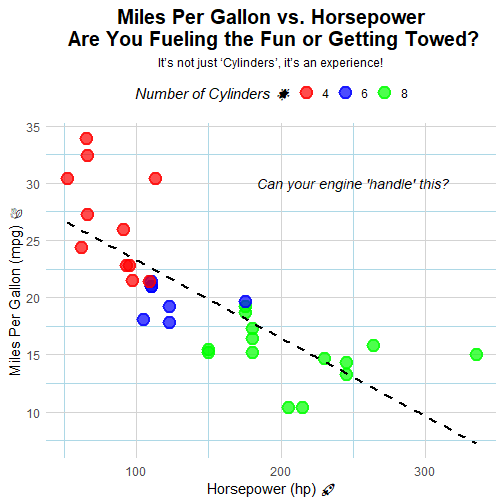
Creating custom prompt wraps
See prompt_wrap() and the ‘Creating prompt wraps’ vignette
for information on how to create your own prompt wraps.